domingo, diciembre 04, 2005
El extremo de atrás
Después de la etapa de comprobación de tipos, queda la generación del código intermedio. En este proyecto se pueden aplicar ciertas simplificaciones que son de mucha utilidad; tal como el asumir que todo error que se pueda capturar en la etapa de parseo, se capturará ahi, de manera que el código intermedio quedará de una vez, limpio y libre de errores.
Tal como su nombre lo indica, este producto representa el punto limítrofe entre la parte frontal y la posterior del compilador. Es interesante notar, que la representación intermedia es por sí misma, un lenguaje, y como tal es lejanamente factible escribir código de programación directamente en una representación "neutral". En teoría, cualquier lenguaje fuente puede traducirse a un determinado código intermedio, y un codigo intermedio puede traducirse a código fuente de otro lenguaje, ensamblador o código objeto(binario) de cualquier máquina. El código intermedio es, de todas formas, casi tan confuso de entender como el propio ensamblador, y varía demasiado, pues, a pesar de existir ciertos patrones de diseño, queda a conveniencia de autor del compilador utilizar la técnica que mejor se ajuste a la orientación que se adopte para el compilador.
Lo anterior me lleva a concluir que seguramente, cuando se traduce de código intermedio hacia cualquier otro, se debe asumir que fué generado por la parte frontal de un compilador y que por lo tanto, está libre de errores, ya que sería un desperdicio de recursos el hacer verificaciones en esta etapa intermedia. En el caso de este proyecto, resulta mucho más cómodo y seguro, producir el código intermedio como una estructura de datos y trabajar "en memoria", para evitar el tenr que pasar por un archivo, como es el caso de muchos compiladores profesionales. Queda claro, que ese archivo se utiliza bien por limitaciones técnicas, o por razones tales como el enlace de código escrito en varios archivos fuente distintos(probablemente en distintos lenguajes).
Otra conclusión importante, es que el uso de la tabla de símbolos es tan necesario y provechoso tanto en la etapa frontal como en la posterior; asimismo la libertad de diseño que permiten las herramientas modernas tales como el lenguaje JAVA y las computadoras de (por ahora)alta capacidad, como las actuales, facilitan sobremanera la realización de un compilador, ya que se eliminan muchas de las restricciones de espacio en memoria, algunos de los problemas de rendimiento(cuando se trate de compiladores pequeños a medianos) y el tamaño del código del compilador propiamente dicho. Aparentemente, de esta ventaja se a abusado en plataformas tales como .NET (joke?).
Implementacion de la representación intermedia.
Hay dos formas casi diferentes de implementar el código intermedio. La que he preferido es la de construir un arbol de sintaxis abstracta linealizado, utilizando una estructura de ArrayList, donde se guardan estructuras que hacen el papel de Cuads. Estas estructuras constan de un operador, dos operandos, y un resultado. Dependiendo del operador se evaluan los operandos, pudiendo éstos representar valores inmediatos, como en las hojas del árbol, o bien cursores a otras casillas en el mismo ArrayList, como en el caso de los nodos interiores. Los operandos pueden también representar índices de la Tabla de símbolos.
En este proyecto, el Arbol de sintaxis abstracta se construye de forma que siempre, al momento de crear un nodo que tiene hijos, éstos han sido previamente creados. Por otra parte, cada vez que se crea un nodo(u hoja), se inserta en la lista, y se retorna el índice en el cual sucedió la inserción, incrementando en uno el índice con cada inserción. Estos índices se hacen circular a través de la gramática como atributos sintetizados, permitiendo la fácil creacion de nuevos árboles a partir de los ya existentes. Esta forma de trabajo permite garantizar que para cualquier nodo con hijos, se cumple que el índice de los hijos es siempre menor que el índice del padre.
Este detalle se puede aprovechar de la siguiente manera:
El miembro "resultado" de los cuads se deja vacío al momento de la creación inicial del AST. El AST se recorre de acuerdo al índice de los nodos; siempre se visitará primero a los hijos, por lo cual, se puede asignar correctmente a "resultado" el valor conveniente, ya que cuando el padre de dicho nodo lo requiera, está garantizado que tal valor ya ha sido asignado.
Lo más importante de esta estrategia, es que permite la fácil asignación de registros a las expresiones en el momento del paso de la representación intermedia a ensamblador. Los registros asignados a los hijos se pueden liberar cuando se calcula el valor del padre.
Por otra parte, el asignar el resultado de los operadores binarios a uno de los registros de los operandos reduce el numero de registros necesarios para ciertos cálculos: por ejemplo para 3 + 4, en lugar de
add $t2, $t0, $t1
se puede hacer asi:
add $t0, $t0, $t1
de esta forma, se evita el tener que buscar un registro libre para el resultado, y se evita la operacion de liberar uno de los registros.
La parte referenta a los stack frames, resulta severamente difícil de entender, sin embargo no es igual de programar, ya que se trata en realidad de un segmento de código que es constante, al menos parcialmente. Claro, que esto ayudado en gran medida por la simplificación de usar palabras tanto para enteros como caracteres. Aun queda por resolver la temática de los arreglos, no obstante, parece sensato comprobar primero que las variables de tamaño constante son correctamente procesadas para despues comenzar con los arreglos. Con esto en mente, es recomendable calcular los despazamientos(offset) de manera incremental y no multiplicativa, ya que arreglos de cualquier tamaño pueden declararse entre variables de tamaño constante, por lo que simplemente multiplicar el numero de orden de declaración por el ancho de palabra es un tanto contraproducente.
En un comentario final, las estructuras de control ofrecen también un reto de estudio, pues, dado que el asembler se ejecuta secuencialmente, se debe analizar bien la colocación de los saltos y bifurcaiones.
domingo, noviembre 27, 2005
Convenciones de llamada y parametros variantes
Fuera de eso, lo más que sé al respecto, es que, MIPS es arquitectura RISC, mientras INTEL es CISC. Eso significa que MIPS posee un juego de Instrucciones reducido, mientras que Intel, tiene uno extendido. En lo que a mi respecta, eso significa que Intel tiene instrucciones equivalente a la secuencia de Varias instrucciones, lo cual por ejemplo, permite que lo que MIPS hace en dos o más instrucciones, INTEL lo puede hacer en una sola instruccion atómica.
En Realidad, el tema RISC vrs CISC es sumamente extenso, dado que se trata de filosofías de diseño, y como tales, tienen ventajas y desventajas...
En cuanto a la segunda pregunta, pues, si, en efecto hice el programa, pero solo fue "un vil copy-paste" de un ejemplo que encontre en MSDN.
De modo que decidí hacer algo parecido, pero escarbando un poquito, usando direcciones de memoria para ver algunas cosas...
Lo primero que hice, es ver la direccion de memoria de los parámetros, para constatar sus posiciones relativas en la menmoria. Pude confirmar, que C, introduce primero el último parámetro, dejando el primero más cerca del tope del stack. En el ejemplo que proporciono se puede ver como second está en la direccion de memoria siguiente a first.
Eso me indujo a mi siguiente experimento. Dado el procedimiento cuyos parámetros son todos de tipo int, es posible declarar un int*, y asignarle la direccion del primer parámetro. El resultado, si se tiene:
int * ptr = &primerParam
Entonces se puede decir:
ptr[0] = ///
ptr[1] = ///
/// = ptr[n],
donde ptr[n] es el (n+1)-ésimo parámetro.
En mi experimento, pude accesar todos los parámetros, indistintamente si éstos eran fijos o variantes.
ABRE-PARENTESIS
No hay manera de saber cuantos parámetros se han enviado, al menos desde el lado del callee, si no se utiliza algun terminador, bandera, valor especial, ... etc. ni siquiera mediante las macros va_start, va_arg, o va_end (que no se que hace por cierto), y esto, aun en las versiones ansi y unix.
Solamente el caller "sabe exactamente" cuantos argumentos utilizó en la llamada.
Aqui entra en juego el asunto de las CALLING_CONVENTIONS.
En las lecturas que hice, encontré lo siguiente:
hay basicamente tres: __stdcall, __cdecl, y __fastcall.
En realidad no encontré una diferencia entre las dos primeras, excepto que en __cdecl, el caller es el responsable de sacar los parametros del stack una vez que la llamada retorna; no así en __stdcall, donde es el callee el encargado.
En cuanto al orden de los parámetros en la pila, experimenté con __stdcall y con __cdecl, en ambas obtuve las mismas direcciones relativas entre parámetros, i.e. no vi ningun cambio, el primer argumento está siempre mas cerca del tope de la pila que los demás.
De hecho, eso también lo leí por ahi en mis averiguatos.
En lo que más relevancia encontre que la diferenciacion era importante, es en el tema ya de enlace de símbolos (linking), donde tienen mucho que estudiar los que desarrollan DLL, (Dynamic Link Libraries). Aqui lo importante es que, si hay una disparidad entre convenciones de llamada, (que un lado utilice __stdcall y el otro __cdecl) la pila se ve destruida, pues bien, o nadie hace "pop", o ambos lo harán, ( y la máquina hace "puff" y uno queda con "cara de what?").
En un comantario sin importancia, hasta ahora sé porque hay que ponerle __stdcall a las funciones que uno usa en una DLL, jeje, por cierto, eso de #define, es mala manía, porque en las DLL uno usa DLLIMPORT, pero al final, #define DLLIMPORT __stdcall. (Ni los mareros usan tanto alias...)
La consistencia entre convenciones de llamada es también crucial en los casos en que una aplicación se desarrolla desde varios lenguajes.
en cuanto a __fastcall, basicamente utiliza registros para pasar parámetros, pero como no todos los registros estarán disponibles, a fin de cuentas el compilador terminará decidiendo cuales poner y cuales no...
El otro punto a que encontré, concerniente a convenciones, tiene tambien que ver con linking, esta vez con los nombres decorados o "mangling", que es cuando los editores de enlace (equivalente de linkers) cambian los nombres de las funciones, "decorandolos" con simbologías que indican tipo de convencion de llamada, tipo y/o numero de parametros, etc. El "name mangling" depende del diseño del linker.
CIERRA-PARENTESIS
Tambien quise ver las variables locales, y constaté que se menten en la pila en el orden en que se declaran, y despues que los argumentos, es decir asi:
(direcciones bajas/tope)
...
variables locales
8 Bytes que no se que son
arg1
arg2
...
argn
...
(direcciones altas/fondo de pila)
Codigo Usado en el experimento final:
____________________________________________
#include
#include
#include
int recorre4(int first, int second, int third...){
printf("&first =%i\n&second=%i\n&third =%i\n",&first, &second, &third);
int a,b,c,d;
a = 1;
b = 2;
c = 3;
d = 4;
printf("\n&a=%i\n&b=%i\n&c=%i\n&d=%i\n",&a,&b,&c,&d);
int* ptr; ptr = &first;
printf("&p=%i\n",&ptr);
int x,y,z;
printf("\n&x=%i\n&y=%i\n&z=%i\n",&x,&y,&z);
printf("ptr:[%i][%i][%i][%i][%i][%i]\n",ptr[0],ptr[1],ptr[2],ptr[3],ptr[4],ptr[5]);
printf("ptr[7] = = = :%i\n", ptr[7]);
printf("ptr[6] = = = :%i\n", ptr[6]);
printf("arriba^5 de a:%i\n", *(&a+5));
printf("arriba^4 de a:%i\n", *(&a+4));
printf("arriba^3 de a:%i\n", *(&a+3));
printf("arriba^2 de a:%i\n", *(&a+2));
printf("arriba de a:%i\n", *(&a+1));
printf("arriba de b:%i\n", *(&b+1));
printf("arriba de c:%i\n", *(&c+1));
printf("exactamente c:%i\n", *(&c));
printf("debajo de c:%i\n", *(&c-1));
printf("debajo^2 de c:%i\n", *(&c-2));
printf("debajo^3 de c:%i\n", *(&c-3));
//return 224;
}
int __stdcall normal(int m, int n, int o){
int s, t, u;
printf("&m := %i\n", &m);
printf("&n := %i\n", &n);
printf("&o := %i\n", &o);
printf("&s := %i\n", &s);
printf("&t := %i\n", &t);
printf("&u := %i\n", &u);
}
int main(){
int r1 = recorre4(2,5,6,7,8,0);
printf(" retorna %i\n", r1);
int r2 = recorre4(2,5,6,7,8,0);
printf(" retorna %i\n", r2);
printf("\n");
system("pause");
normal(1,2,3);
system("pause");
return 0;
}
____________________________________________
SALIDA
____________________________________________
&first =37814056
&second=37814060
&third =37814064
&a=37814044
&b=37814040
&c=37814036
&d=37814032
&p=37814028
&x=37814024
&y=37814020
&z=37814016
ptr:[2][5][6][7][8][0]
ptr[7] = = = :4200443
ptr[6] = = = :37814112
arriba^5 de a:6
arriba^4 de a:5
arriba^3 de a:2
arriba^2 de a:4200463
arriba de a:37814112
arriba de b:1
arriba de c:2
exactamente c:3
debajo de c:4
debajo^2 de c:37814056
debajo^3 de c:4200624
retorna 22
&first =37814056
&second=37814060
&third =37814064
&a=37814044
&b=37814040
&c=37814036
&d=37814032
&p=37814028
&x=37814024
&y=37814020
&z=37814016
ptr:[2][5][6][7][8][0]
ptr[7] = = = :4200443
ptr[6] = = = :37814112
arriba^5 de a:6
arriba^4 de a:5
arriba^3 de a:2
arriba^2 de a:4200511
arriba de a:37814112
arriba de b:1
arriba de c:2
exactamente c:3
debajo de c:4
debajo^2 de c:37814056
debajo^3 de c:2147332096
retorna 25
Press any key to continue . . .
&m := 37814072
&n := 37814076
&o := 37814080
&s := 37814060
&t := 37814056
&u := 37814052
Press any key to continue . . .
____________________________________________
lunes, noviembre 14, 2005
Uso de atributos heredados en CUP(parte 2)
Esta vez utilicé una gramatica similar a la declaración de tipos en C/C++;
la cual es:
dec -> dec tipo lista ';'
dec -> tipo lista ';'
tipo -> entero
tipo -> real
lista -> lista ',' ID
lista -> ID
Las reglas semanticas embebidas en la gramatica, originalmente quedan:
dec -> dec tipo {lista.t = tipo.t} lista ';'
dec -> tipo {lista.t = tipo.t} lista ';'
tipo -> entero {tipo.t = entero}
tipo -> real {tipo.t = real}
lista -> {lista1.t = lista.t} lista ',' ID {declare(ID.lexema, lista.t);}
lista -> ID{declare(ID.lexema, lista.t);}
por la regla de copia, se sustituyen las referencias al atr.heredado por referencias al
atributo sintetizado del símbolo de orígen, por lo tanto, las producciones de lista
quedan:
lista -> lista ',' ID {declare(ID.lexema, lista.t);} // usando atr[top-3]
lista -> ID{declare(ID.lexema, lista.t);} // usando atr[top-1]
aca pueden ver el código de cup.
----------------------------------------------------------------
package EjemploH1;
import java.io.*;
import java_cup.runtime.*;
parser code {:
public static void main(String args[]) throws Exception {
try{
//FileReader fis = new FileReader("dec.txt"); // se construye el File reader
parser paspar = new parser(new Yylex(System.in));
paspar.parse();
System.out.println("Proceso terminado");
System.exit(0);
}catch(FileNotFoundException e){
System.out.println("Imposible abrir el erchivo especificado");
System.exit(1);
}
}
:}
action code {:
private void settype(String id, String tipo){
System.out.println("declare(" + id + ", tipo " + tipo + ");");
}
:}
terminal ENTERO, REAL, COMA, PUNTOYCOMA;
terminal String ID;
non terminal cSimbolo dec, tipo, lista;
dec ::= dec tipo lista PUNTOYCOMA;
dec ::= tipo lista PUNTOYCOMA;
tipo ::= ENTERO {:RESULT = new cSimbolo("entero"); :};
tipo ::= REAL {:RESULT = new cSimbolo("real"); :};
lista ::= lista COMA ID:i{:settype(i,((cSimbolo)((java_cup.runtime.Symbol)
CUP$parser$stack.elementAt(CUP$parser$top-3)).value).tipo);:};
lista ::= ID:i {:settype(i,((cSimbolo)((java_cup.runtime.Symbol)
CUP$parser$stack.elementAt(CUP$parser$top-1)).value).tipo);:};
----------------------------------------------------------------
Aqui un ejemplo de corrida:
----------------------------------------------------------------
entero lunes, martes, miercoles; real madrid, fantasia, cuento;
declare(lunes, tipo entero);
declare(martes, tipo entero);
declare(miercoles, tipo entero);
declare(madrid, tipo real);
declare(fantasia, tipo real);
declare(cuento, tipo real);
^Z
Proceso terminado
Press any key to continue...
----------------------------------------------------------------
y por si las dudas, el código de jFlex:
----------------------------------------------------------------
package EjemploH1;
import java_cup.runtime.Symbol;
/**
* Class YyLex, creada mediante jFlex a partir de minimal. lex.
* @author Gerson Lara
* @URL http://www2.cs.tum.edu/projects/cup/minimal.tar.gz
*/
%%
%cup
%ignorecase
%%
";" { return new Symbol(sym.PUNTOYCOMA); }
"entero" { return new Symbol(sym.ENTERO); }
"real" { return new Symbol(sym.REAL); }
"," { return new Symbol(sym.COMA); }
[A-Za-z]+ { return new Symbol(sym.ID, yytext()); }
[ \t\r\n\f] { /* ignore white space. */ }
. { System.err.println("Illegal character: "+yytext()); }
----------------------------------------------------------------
domingo, noviembre 13, 2005
Cambios en la carrera.
Lo que queiro mencionar aquí es mi satisfacción por el hecho de que ahora se va a considerar la falla (ya mencionada antes) de la gente de sistemas para trabajar en grupos multidisciplinarios.
Me permito recordar que si bien es cierto, la carrera es eminenetemente técnica, eventualmete nos corresponderá fungir como administradores de algun departamento o empresa, deseablemente relativa al tema computacional. Y esto lo digo no con ánimos de insistir, sino de apoyar esa decisión en particular de la jefatura de la carrera.
En mi posición particular, el software administrativo, no me agrada (aunque quizá sea el que más venda), prefiero verme como parte de un equipo de desarrollo o investigación sobre nuevas tecnologías, o apoyar proyectos de investigación científica o algo así. Aquí inserto mi frase de "La computación por sí sola no sirve para nada". Digo esto porque (no lo tomen a mal pero,) un autómata ahi solito, sólo sirve para quebrarse la cabeza. Ahora, asocie ese autómata con um problema real, y al resolver el autómata, debería tener la solución del problema original. Suena obvio, y creo que lo es, sin embargo, al trasladar esto un poco más a flote, La gente de Sistemas tiende a pensar que con saber de Sistemas y computadores, bits y bytes, y si se queire cables y frecuencias basta. Pero y a la hora de desarrollar un proyecto que integre personas y tecnología? quién sabe de personas? De alumnos un docente, de pacientes el doctor, de empleados el de Recursos Humanos que con suerte es Psicólogo... La computación sirve cuando se le combina adecuadamente con otra ciencia, arte, deporte, empleo etc... El caso es que, con suerte( no se si buena o mala) me corresponderá algún día, liderar o administrar un grupo como esos, donde cada quien piensa que su propio gremio es lo máximo. ¿Cómo ponerlos de acuerdo?
Por eso creo que le viene bien a Sistemas de Unitec, la carrera "donde se enseña cómo hacer y no cómo usar..." , que le incluyan un par de clases y talleres de liderazgo, para aprender a quitarnos eso de "Porque si, porque yo se de computadoras y (vos | usted | etc ) no!" (Que aunque no lo decimos, lo pensamos)
Una de las últimas clases que incluye el plan 2002 para sistemas, donde se puede trabajar en grupos multidisciplinarios, es Generación de Empresas I, clase que en lo personal, opino que es un desastre; vayan a ver a los de Sistemas, Todos Juntos!!!! Parece que le tienen miedo a los de Publicidad y por eso no se juntan con ellos, como si les fueran a robar los poderes divinos o algo.
Finalmente, comento que alguien me dijo, que en su caso, cuando estudió, era requisito, que en cada período, debía inscribir una clase al menos, no relacionada con el área, es decir, Finanzas, Biología, Arte, ... Unitec podría hacer eso, aunque copiar comportamientos nunca es bueno, eso si los iba a enojar, en lugar de eso, ahi colocaron unos talleres no más, asi que ¡Enhorabuena por los cambios!!!
Uso de Atributos heredados en CUP (parte 1)
La verdad solamente había vista la punta de in iceberg.
Al intentar colocar acciones enmbebidas en la gramática se genera una cantidad alta de conflictos shift/reduce; el insertar los marcadores manualmente, procuce (al menos en mis pruebas) exactamente los mismos conflictos.
El mayor problema con esos conflictos, es que , aunque CUP tiene una políitica establecida para resolverlos, también aborta la generación de código, por lo cual, nunca pude probar si mi especulación era correcta.
El código que pensaba emplear eran las respectivas versiones de algo como esto:
cSimbolo E = (cSimbolo)((java_cup.runtime.Symbol) CUP$parser$stack.elementAt(CUP$parser$top-2)).value;
Pero el problema no fue escribir eso, sino hacer que CUP generase el código.
De modo que sigo con la interrogante a cuestas.
Por cierto, aun me queda otra duda:
Si en A -> XYZ, o mejor en S -> XYZ, donde S es el START SYMBOL o uno similar, ¿Cómo puede utilizarse un atributo de S en los hijos de S? ¿No ha reducido ni se ha metido en la pila, entonces de donde toma su valor? y ya que estamos, fuera de ese caso, ¿Para cualquier necesidad de un valor de atributo de Y por parte de un hijo de Y, debe sustituirse por el correspondiente atributo del símbolo del cual hereda el atributo? o hay casos donde no es posible ?(Sólo en L-atribuidas)
domingo, noviembre 06, 2005
Tarea
P -> D;E
D -> D;D
D -> id:T { declare(id.nombre, T.tipo) }
T -> char { T.tipo = char }
T -> integer { T.tipo = integer }
T -> list of T1 { T.tipo = tipo_lista(T1.tipo) }
E -> literal { E.tipo = char }
E -> num { E.tipo = integer }
E -> id { E.tipo = tipode(id.nombre) }
E -> ( L ) { E.tipo = L.tipo }
L -> E,L1 { L.tipo = si( E.tipo==(L1.tipo).tipo, tipo_lista(E.tipo, L1.tipo), error_tipo) }
L -> E { L.tipo = E.tipo }
Notas: asuma que: declare() graba a la TDS, tipode() busca en la TDS y retorna el tipo y si() es una funcion que toma un valor booleano y dos expresiones, si el valor es true, retorna el valor de la primera expresion, sino el de la segunda.
EJERCICIO 6.5a (interprete lo que está entre llaves como las "decoraciones del arbol". El árbol está dibujado como en el "treeview" de windows.)
P
+-D
| +-D {declara(id.lexema, T.tipo)}
| | +-id {id.lexema = "c"}
| | | +-c
| | +-:
| | +-T {T.tipo = char}
| | +-char
| +-;
| +-D {declara(id.lexema, T.tipo)}
| +-id {id.lexema = "i"}
| | +-i
| +-:
| +-T {T.tipo = integer}
| +-integer
+-;
+-E {E1.tipo==char && E2.tipo==integer entornces error_tipo}
+-E1 {E1.tipo = tipode(id.lexema)//char}
| +-id {id.lexema="c"}
| +-c
+-mod
+-E2 {E3.tipo==integer && E4.tipo==integer entonces integer}
+-E3 {E3.tipo=tipode(id.lexema)//integer}
| +-id {id.lexema="i"}
| +-i
+-mod
+-E4 {E.tipo = integer}
+-num
+-3
TDS:[id,tipo]
[c,char]
[i,ineger]
EJERCICIO 6.5b
P
+-D
| +-D { declare(id.lexema, T1.tipo) }
| | +-id {id.lexema="p"}
| | | +-p
| | +-:
| | +-T1 {T1.tipo = pointer(integer)}
| | +-^
| | +-integer
| +-;
| +-D {declare(id.lexema,T3.tipo)}
| +-id {id.lexema = "a"}
| | +-a
| +-:
| +-T3 {T3.tipo = array(num.val, T2.tipo)}
| +-array
| +-[
| +-num {num.val = 10}
| | +-10
| +-]
| +-of
| +-T2 {T2.tipo = integer}
| +-integer
+-;
+-E {E.tipo = E3.tipo == integer && E1.tipo == array(s,t) entonces t //integer}
+-E1 {E1.tipo = tipode(id.lexema)//array(10,integer)}
| +-id {id.lexema = "a"}
| +-a
+-[
+-E3 {E3.tipo = E2.tipo==pointer(t1) entonces t1 //integer}
| +-E2 {E2.tipo = tipode(id.lexema)//pointer(integer)}
| | +-id {id.lexema = "p"}
| | +-p
| +-^
+-]
TDS:[id,tipo]
[p:pointer(integer)]
[a:array(10,integer)]
EJERCICIO 6.5C
Asumiendo que existe
E -> E(E)
P -> D;S
S -> id := E
S -> if E then S1
S -> while E do S1
S -> S1;S2
P
+-D
| +-D {declare (id.lexema,T3.tipo)}
| | +-id {id.lexema="f"}
| | +-:
| | +-T3 {T3.tipo = (T1.tipo->T2.tipo)//(integer->boolean)
| | +-T1 {T1.tipo = integer}
| | | +-integer
| | +-'->'
| | +-T2 {T2.tipo = boolean}
| | +-boolean
| +-;
| +-D
| +-D {declare(id.lexema,T4.tipo)}
| | +-id {id.lexema = "i"}
| | +-:
| | +-T4 {T4.tipo = integer}
| | +-integer
| +-;
| +-D
| +-D
| | +-id {id.lexema="j"}
| | +-T5 {T5.tipo=ingeter}
| | +-integer
| +-;
| +-D {declare(id.lexema,T6.tipo)}
| +-id {id.lexema="k"}
| +-:
| +-T6 {T6.tipo=integer}
| +-integer
+-;
+-S6 {S6.tipo = E3.tipo==boolean entonces S5.tipo //vacio}
+-while
+-E3 {E3.tipo = E2.tipo==integer && E1.tipo=(integer->boolean) entonces boolean}
| +-E1 {E1.tipo = tipode(id.lexema)//(integer->boolean)}
| | +-id {id.lexema="f"}
| +-(
| +-E2 {E2.tipo=tipode(id.lexema)//integer}
| | +-id {id.lexema="i"}
| +-)
+-do
+-S5 {S5.tipo = S1.tipo == vacio && S4.tipo == vacio entonces vacio}
+-S1 {S1.tipo = tipode(id.lexema)== E4.tipo entonces vacio;}
| +-id {id.lexema="k"}
| +-:=
| +-E4 {E4.tipo=tipode(id.lexema)//integer}
| +-id {id.lexema="i"}
+-;
+-S4 {S4.tipo = S2.tipo == vacio && S3.tipo == vacio entonces vacio}
+-S2 {S2.tipo = tipode(id.lexema)== E7.tipo entonces vacio}
| +-id {id.lexema="i"}
| +-:=
| +-E7 {E7 = E5.tipo ==integer && E6.tipo ==integer entonces integer}
| +-E5 {E5.tipo = tipode(id.lexema)//integer}
| | +-id {id.lexema="j"}
| +-mod
| +-E6 {E6.tipo = tipode(id.lexema)//integer}
| +-id {id.lexema="i"}
+-;
+-S3 {S3.tipo = tipode(id.lexema)==E8.tipo entonces vacio}
+-id {id.lexema="j"}
+-:=
+-E8 {E8.tipo=tipode(id.lexema)//integer}
+-id {id.lexema="k"}
TDS:[id,tipo]
[f,integer->boolean]
[i,integer]
[j,integer]
[k,integer]
domingo, octubre 30, 2005
El primer disque compilador de mi existencia
Asi se siente poner en marcha un pequeno compilador de sumas para mips. bueno, spim... (ni es lo mismo ni es igual)
Eso me recuerda que cuando inicie mis estudios, mi papá me preguntó que como era que los ceros y unos se convertian en un programa, y como era que la computadora los hace funcionar.
Hasta ahora, cuatro años después podría decirle una respuesta...
Para iniciar, recuerdan el ejemplo minimal? pues, bien, utilicé el archivo minimal.lex, y modifiqué minimal.cup.
package Ejemplos;
import java_cup.runtime.*;
import java.util.LinkedList;
parser code {:
public static void main(String args[]) throws Exception {
new parser(new Yylex(System.in)).parse();
}
:}
action code {:
private boolean[] usoReg = new boolean[8];
private String getFreeReg(){
for(int i = 0; i < i =" (int)(reg.charAt(2)" nreg =" getFreeReg();" result =" new" reg =" nReg;" result =" new" reg =" T.reg;" nreg =" getFreeReg();" result =" new" reg =" nReg;" result =" new" reg =" F.reg;" nreg =" getFreeReg();" result =" new" reg =" nReg;" style="font-family:georgia;">La parte de la gramática es igual que el ejemplo en clase, salvo unas pequeñas modificaciones.
aca lo interesante es la funciopn para tomar un registro y para liberarlo. No son nada del otro mundo vdd?
Dado este código de cup, generando, compilando y corriendo, se abre la consola, donde hay que escribir la cadena de sumas y multiplicaciones, terminados con puntoycoma, aqui pueden ver el ejemplo de corrida:
----------------------------
2+3*8+6*9*5;
li $t0 , 2
li $t1 , 3
li $t2 , 8
mul $t3 , $t1 , $t2
#queda libre $t1(1
#queda libre $t2(2
add $t1 , $t0 , $t3
#queda libre $t0(0
#queda libre $t3(3
li $t0 , 6
li $t2 , 9
mul $t3 , $t0 , $t2
#queda libre $t0(0
#queda libre $t2(2
li $t0 , 5
mul $t2 , $t3 , $t0
#queda libre $t3(3
#queda libre $t0(0
add $t0 , $t1 , $t2
#queda libre $t1(1
#queda libre $t2(2
#se escribe el resultado
li $v0, 1
add $a0, $zero, $t0
syscall
terminamos?
------------------------ '
otro ejemplo:
------------------------
3*9*2*4*5;
li $t0 , 3
li $t1 , 9
mul $t2 , $t0 , $t1
#queda libre $t0(0
#queda libre $t1(1
li $t0 , 2
mul $t1 , $t2 , $t0
#queda libre $t2(2
#queda libre $t0(0
li $t0 , 4
mul $t2 , $t1 , $t0
#queda libre $t1(1
#queda libre $t0(0
li $t0 , 5
mul $t1 , $t2 , $t0
#queda libre $t2(2
#queda libre $t0(0
#se escribe el resultado
li $v0, 1
add $a0, $zero, $t1
syscall
#terminamos?
----------------------
Como es obvio, falta la parte de las directivas y todo ese rollo... por los momentos mis pruebas las hice mediante copy-paste. Con ver que el resultado correcto se desplegara en la consola, me bastaba.
Claro, que no salio a la primera, en varios intentos, mi codogo salia escrito con errores de sintaxis, pero eso es naturalmente debido a la falta de práctica con MIPS.
Una Hashtable con múltiples objetos bajo la misma llave
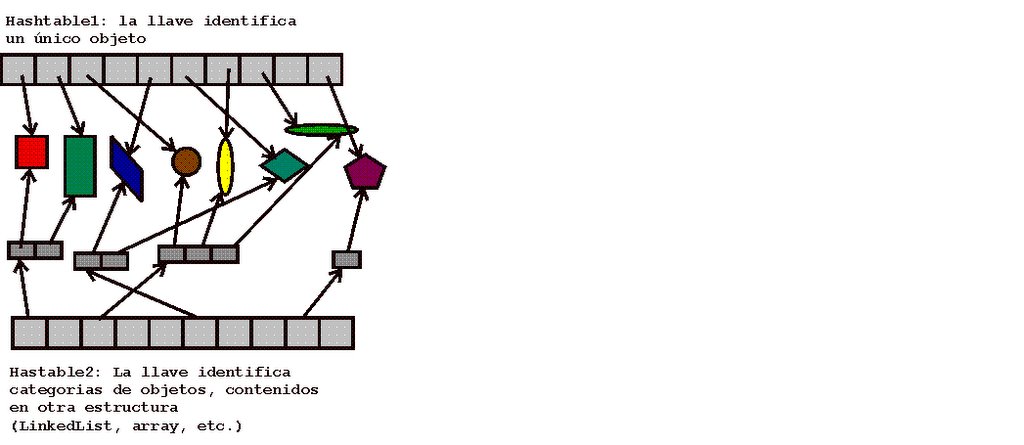
En mi proyecto, la tabla de símbolos está implementada mediante una tabla hash que contiene objetos entre cuyos campos están el nombre y el ámbito. La llave de dichos objetos se calcula entonces concatenando el valor del ámbito, cuatro puntos (“::”) y el valor del nombre.
Esto tiene la ventaja de que rápidamente se puede averiguar si existe ya un identificador con un nombre dado en el ámbito especificado, pues basta con calcular la llave y preguntarle a la Hashtable mediante el método containsKey. La dificultad que esto me propuso, era el problema de cómo recuperar TODOS los identificadores dado un ámbito, i.e. dado el nombre de una función o procedimiento, recuperar tanto parámetros como variables locales.
Primero, y para no hacer un recorrido estilo Programación 1 en busca de todas las instancias cuyo campo ámbito correspondiera, quise averiguar si hay una forma de que la tabla hash pudiese mapear una sola llave a varios objetos. Aun no se si se puede, pero javadoc dice que “el nuevo valor asociado reemplaza al valor anterior”. Busqué dentro del mismo javadoc a ver si existe otra estructura capaz de hacer el trabajo; la búsqueda fue infructuosa. Ya sin ideas, pregunté a compañeros y profesores. La mayoría me sugiere que cree mi propia clase, y un compañero me sugirió que usara una tabla hash por ámbito en la cual guardase tablas hash por nombre.
Lo primero es: combinar esas dos sugerencias. Creo que funcionaría, pero me complicaría los procedimientos de inserción y búsqueda de símbolos, que ya está programada y probada.
Decidí hacer lo siguiente: 1) Mantener mi tabla de símbolos tal y como está hasta ahora. 2) Agregar una segunda tabla hash, donde las llaves son ámbitos y los valores son LinkedList que apuntan a los mismos objetos que están en la tabla original.
De esa forma, la lista de los identificadores pertenecientes a un ámbito está “siempre lista y servida para llevar”.
Ya realicé los primeros ensayos. La inserción en ambas tablas se hace sin problemas, y aunque para terminar de hacer útil esa segunda tabla de símbolos hace falta un par de adiciones, ya se ve que cumple los objetivos.
El principal uso que pretendo darle es principalmente para comprobar los tipos de los parámetros en las llamadas a funciones, Aunque aun no estoy 100% seguro de cómo hacer eso... jeje.
martes, octubre 25, 2005
Assembler en MIPS
Comentarios generales:
El laboratorio fue fácil de hacer, las dificultades, como siempre aparecen haciendo más interesante el rollo.
Instalé la versión que venia en el CD que encontré en el parqueo, eso no dio problemas.
Luego, copiar el codigo del ejemplo de suma, pues valla! esta vez copié bien!!!. La carga se hizo bien, probé y funcionó.
Hasta aquí todo bien, el problema fue que suspendi el laboratorio y lo retome hasta el lunes en la noche.
Para ser honestos, mejor ví algunos blogs de los compañeros, y lógico, mi codigo no salio tan diferente, asi que solo voy a relatar algunas cosas que por lo menos no estaban en los blogs que YO VI.
1. para ahorrarme el error de escribir mal $zero, aprendi a usar la y move. tambien escribo menos .
2. aprendi a usar jal, porque mi programa ejecutava en ciertas ocasiones "tanto el if como el else", entonces decidi usar jal para tirar la ejecucion hasta despues del "cuerpo del else".
3. Quise usar las cadenas directamente en la instruccion, sin usar cadn, pero no halle el modo, si es que existe.
4. No se como funciona el modo de ejecucion por pasos, ya que le coloco cualquier numero de pasos en la caja correspondiente pero no veo que pase nada, no veo que cambien los registros, asi que, me conformé con verlos mientras el programita "esperaba el entero"
Comentarios finales
El Assembler de MIPS es para mí {mucho}* más fácil que el de Intel. Con sólo ver el codigo de suma, sabía por donde "iba la cosa". Me dió por revisar uno de los viejos ejemplos de cuando cursé "Organizacion de Computadoras" o "Diseño Lógico Digital"(no recuerdo cual es cual, deberían llamarse las dos del mismo modo, con I y II como todas las demás), y no se que dice ahi. (asembler de intel...)
Hacerle las modificaciones al código no fue difícil, excepto por que si se comete un error el simulador no lo informa como solemos estar acustumbrados, y hay que rebuscar un poquito pero "eso se lima con el uso".
Una vez más, lamento lo escueto del contenido de la clase antes mencionada, ya que el asunto del ensamblador es sumamente interesante, no tanto a nivel de programaciónes sencillas, sino a nivel de análisis como en las llamadas de procedimientos(que no he visto en detalle pero se que estan en "el apendice", y habría sido macanudo tener una clase en hondureño al respecto. Eso lo digo porqeu siempre que busco algo en Internet , me pierdo y termino averiguando otra cosa que nada tiene relacionado con lo que incialmente buscaba.
![]()
