domingo, agosto 28, 2005
Integración Total y los Cuarenta Tokens
Entre otras actividades no muy productivas relacionadas con el compilador, comento que es bastante cómodo tener sintaxis coloreada en los archivos de cup y flex. En jCreator 2.00 es bastante fácil, pues entre las configuraciones del editor, uno puede escoger bajo el nodo Editor/Default, un archivo de sintaxis.
Debo decir que me resulto muy fácil crear un nuevo archivo.syn para la versión 2.00, que usa un simple archivo de texto, no obstante la versión 3.50 de jCreator, usa un archivo en formato xml, el cual no quise indagar.
El siguiente paso sería escoger que colores desea usar.
Por alguna razón insisto bastante con los colores, siempre paso un tiempo considerable con ello, como dije antes, esa es [una de mis tantas] manía[s].
Integración Total
Muchos me han preguntado como generar el Javadoc usando jCreator. Ignoro como se hace en otras versiones, pero la versión 2.00 no tiene el comando a la vista entre los menús.
La idea que me vino a la mente, no es osa del otro mundo: Si configuré dos herramientas para generar código, como fue el caso de los archivos.bat que mencioné en el blog anterior, ¿Cuál es la diferencia con Javadoc? Sólo dos: No se usa un .bat, sino un .exe y no se genera código de java, sino de HTML.
Asi es, los pasos son los mismos, solo hay que fijarse un poco con los comandos:
primero, al elegir el nuevo programa, dirigirse a la carpeta donde estan los programas de la JVM, en mi caso esto era:
C:\j2sdk1.4.2_04\bin
Después al configurar la herramienta, usar los siguientes campos:
Commands = C:\j2sdk1.4.2_04\bin\javadoc.exe -d doc -private
Arguments = $[JavaFiles]
Initial Directory = $[PrjDir]
La opción -d permite especificar un directorio de salida, en mi caso -d doc usará una carpeta llamada doc, la cual creé previamente en la carpeta del proyecto ($[PrjDir]), esto para evitar que los elementos del Javadoc se mezclen y/o confundan con mis archivos de código fuente.
La opción -private hace que se incluyan las clases privadas. Sin esta opción, no me documentaba la clase Yylex. (Agradecemos la colaboración de Osman Santos en la averiguación de este pequeño detalle)
Para el campo Arguments, recomiendo utilizar el boton que despliega el menu, y utilizar la opción Project Java Files, y en Initial Directory, la opción Project Directory.
Los Cuarenta Tokens
Lo admito: ¡me encanta jFlex!
Comparándolo con los recuerdos de mi experiencia con ANTLR, puedo afirmar que me siento mucho más confiado con JFLEX.
Aunque al principio no me gustó la documentación, hay que reconocer, que para todo se requiere paciencia, asi que puse esta trillada frase en práctica y leí una buena porción.
Encontré de gran ayuda el ejemplo en el cual especifican parte de la sintaxis de Java, del cual tomé varias ideas, en especial para reconocer strings y secuencias de escape. En realidad no estoy muy seguro de si aplican las secuencias de escape en Pascal, pero por motivos de práctica, intenté hacer que funcionara como en C.
En general, para el lexer, mi estrategia se basa en dos ideas:
1) Los errores deben estar bajo mi control, no bajo el de Yylex, asi los puedo reportar de manera conveniente. y
2) Hay que hacer reglas para aceptar tokens correctos, y reglas para capturar errores.
Lo segundo se debe a algo muy sencillo: si el token está correcto, no hay problema, Yylex lo reconocerá y lo retornará al parser. Pero si el token está mal escrito, Yylex nos dará un extenso y casi ininteligible mensaje de error, ya que el error ocurirá internamente en Yylex, no el el código fuente que estemos analizando.
Además: en algunos puntos es más fácil (con JFlex) hacer las reglas para capturar errores, que hacer expresiones regulares perfectas.
Por ejemplo para los comentarios: es más facil irse a un estado aparte, y tirar el error de anidamiento si encontramos una apertura de comentario, que hecer la expresión regular que admita comentarios sin anidamiento. Aparte, si la ER no reconoce comentarios con anidamiento, el error "lo reportará Yylex", en lugar de "reportarlo yo"
El huevo y la gallina
Para probar el Lexer usé esto:
-------- empieza código -------------
package Jahaz;
import java_cup.runtime.*;
import java.io.*;
/**
Clas Comodo, calache para probar el Yylex solo.
@autor Gerson Lara
*/
public class Comodo{
public static void main(String args[]) throws Exception {
System.out.println("Bienvenido a Comodo");
//Yylex alex = new Yylex(System.in);
FileReader fis = new FileReader("hola.pas");
Yylex alex = new Yylex(fis);
int a = 0;
while(a < 1000){
alex.next_token();
//System.out.print("
a++;
}
}
}
---------- fin de código --------------
Con esto puedo especificar un archivo en el cual coloco una serie de Tokens, que no tienen porque estar en orden gramatical, unos de ellos bien escritos, pero la mayoria de ellos con errores, así me cercioro de que mi lexer captura los errores y los reporta adecuadamente.
Si ese era el huevo, ahora la gallina:
para que el lexer pueda retornar todos los tipos de token, hay que declararlos como terminales en el archivo de CUP y generar y compilar ese codigo, para que la clase sym esté disponible.
Notas sobre los nombres
Mi compilador se llama Comodo ( no es Cómodo, no lleva el acento en la primera o) y como se lo han de imaginar, se debe al Dragón de Comodo, por ser un dragón real que existe hoy en dia.
El lexer se llama Alex por que es un Analizador LEXico
Este compilador será algo así como "El Show de Alex, Parseo y Semita"
Parseo suena como a Perseo, algo griego, pero no se qué. Y Semita por SEMántico.
Si no les da risa, lo entiendo, de por sí, es sabido que no soy bueno para los chistes, y peor a la hora de este post.
Hasta la próxima, ¡y no dejen de buscar al IDEal!!!
lunes, agosto 22, 2005
jFlex & CUP con jCreator
Usando: jCreator 2.00 LE Build 008
Debido a que ya algunos perdimos bastante tiempo con Eclipse, aquí coloco mi forma de configurar jCreator para trabajar con jFlex y CUP
Notras Previas:
Los pasos que aquí detallo son una muestra particular de la manera en que yo realicé la prueba. Este documento fue escrito paralelamente con la realización de la prueba, intentando el máximo de detalle.
Cualquier consulta me la pueden hacer a gerson.lara con la arroba ,gmail el punto y el com, o a mi Telefono de casa(si lo tienen).
OS: Windows XP home en Inglés, versión 2002 con Service pack 2 (instalado desde windows update)
JVM:
C: java -version
java version "1.4.2_04"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.4.2_04-b05)
Java HotSpot(TM) Client VM (build 1.4.2_04-b05, mixed mode)
Computadora: HP con procesador Intel Celeron.
Observación: en las líneas siguientes hago referencia al directorio cmpl, éste es el directorio Complilers_home, o cualquier otro en el cual haya extraído los archivos de jFlex y CUP, y realizado los primeros pasos del Laboratorio #1
- Crear El directorio C:\cmpl\src
- Abrir sesión en jCreator
- Ir a File/New... ,
- Seleccione Workspace/Empty workspace,
- Workspace Name = Inicio
- Location = C:\cmpl\src
- El IDE crea una carpeta nueva: C:\cmpl\src\Inicio
- Ir a File/New...
- Seleccione Projects/Empty Project
- Project name = tDragon,
- El campo Location debe apuntar a la carpeta del workspace
- Asegúrese que esta seleccionada la opción “Add to Current Workspace”
- El IDE crea una carpeta nueva: C:\cmpl\src\Inicio\tDragon
- Ir a File/New...
- Seleccione Files/Text File
- Filename = tDragon.lex.
- Deje el campo Location como está,
- La opción Add to Project en true, y en el combo de abajo el proyecto tDragon (por ahora el único)
- Escriba la especificación léxica (Nota: yo pegué el contenido de minimal.lex)
- Repita pasos similares para el archivo punto-cup.
- Configuración de User Tools parte I: jFlex
- Ubique el archivo jflex.bat, (en mi caso: C:\cmpl\JFlex\bin\jflex.bat), vea más abajo el contenido de este archivo.
- Ir al menú Configure/Options, elija Tools (ojo, ¡no JDK Tools!). En el lado derecho presione NEW / Program y a continuación diríjase a la ubicación del archivo jflex.bat y selecciónelo.
- Aparecerá en el TreeView un nuevo hijo de Tools con el nombre jFlex, selecciónelo para configurar la nueva herramienta.
- En el campo commands debe aparecer de nuevo la ruta y nombre del archivo jflex.bat. Si no es su caso, presione el botón rotulado con los tres puntos y repita la selección del archivo.
- En el campo Arguments elija, mediante el menú que aparece al presionar el botón rotulado con un triángulo, el parámetro “File name”.
- De manera similar Elija “Project Directory” en el campo Initial Directory
- En el recuadro inferior “Tool Options” elija según su conveniencia, recomiendo usar “Save all documents first”
- Si no tiene visible la Barra de Herramientas “Tools”, actívelo en View/Toolbars/Tools
- Ahora una de los botones con icono en forma de llave de tuerca corresponde con jFlex, si ésta era la primera herramienta que configura, será la primera llave.
- Asegúrese de que el editor tiene activo el documento tDragon.lex y pruebe la primera herramienta.
- Revise el directorio del Proyecto (C:\cmpl\src\Inicio\tDragon\), debe haber aparecido el archivo Yylex.java, agréguelo al proyecto. (Menú Project/Add files)
- Configuración de User Tools parte II: Java_cup
- Será necesario crear un nuevo archivo punto-bat en C:\cmpl. (en mi caso C:\cmpl\jcup.bat). Vea más abajo el contenido de este archivo.
- Configure la segunda herramienta igual que en el caso anterior, seleccionando jcup.bat (o su equivalente), los argumentos y directorio inicial, son los mismos.
- Asegúrese de que el editor tiene activo el documento tDragon.cup y pruebe la segunda herramienta.
- Revise nuevamente el directorio del proyecto y compruebe que existen lso nuevos archivos parser.java y sym.java. Agréguelos al aproyecto.
- Diríjase a Project/Project Settings,
- Vaya a Required Libraries y presione NEW.
- Presione Add/Package, y Elija el archivo jflex.jar, que se encuentra en C:\cmpl\JFlex\lib\, en el campo name coloque jFlexJar
- Cuando regrese al diálogo Project Settings, asegúrese que la nueva librería está seleccionada(Marcada con Check)
- Compile el Proyecto (F7) y córralo(F5);
En mi caso, me compilo sin problemas y me corrío lo mismo que en el laboratorio en la parte que se hace en command Line. Aún así, salen errores al compilar los archivos individuales desde jCreator, hay que compilar todo el proyecto.
Contenido de los archivos punto-bat
----- inicio de batch: jFlex.bat ---------
@echo off
REM Edite los path JFLEX_HOME y JAVA_HOME para sus necesidades
REM (No agregue backslashes al final de los paths)
rem set JFLEX_HOME=C:\Compiladores\JFlex
REM only needed for JDK 1.1.x:
rem set JAVA_HOME="C:\Program Files\Java\j2sdk1.4.2"
REM -------------------------------------------------------------------
REM for JDK 1.2
java -Xmx128m -jar C:\cmpl\JFlex\lib\JFlex.jar %1 %2 %3 %4 %5 %6 %7 %8 %9
---------- fin de batch ------------
REM @echo off
REM Creado por Gerson Lara
rem Con el proposito de correr java_cup
REM Usando la misma idea que con jFlex.bat
REM -------------------------------------------------------------------
set CMPL_HOME=C:\cmpl
set JAVA_HOME=C:\j2sdk1.4.2_04\bin
set CLASSPATH=%CMPL_HOME%\Java_cup;%CLASSPATH%
java java_cup.Main %1 %2 %3 %4 %5 %6 %7 %8 %9
---------- fin de batch ------------
domingo, agosto 14, 2005
Un lexer hecho a mano
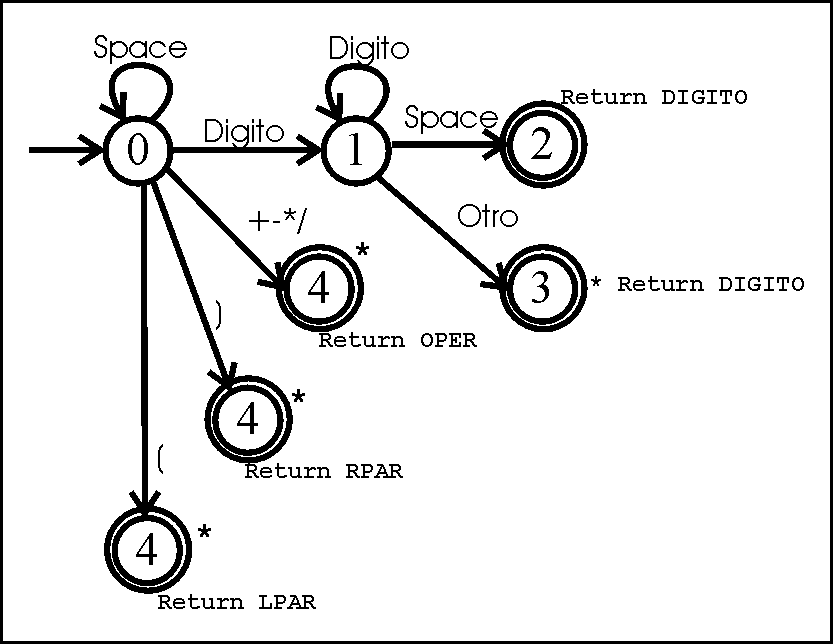
EL proyecto de “Turbo Dragon” está en peligro de extinción.
Aún sigo sin poder conectar efectivamente las herramientas de generación de código con Eclipse. La situación resulta bastante frustrante, para una estudiante de la carrera donde “todo se puede”. Es por esto que he tomado una decisión, de ninguna manera me voy a dejar “ECLIPSAR” por un IDE superconfigurable, así que si mr. E. sigue rebelde, doña Consola, que no me defrauda, me será más que suficiente para hacer un compilador.
En efecto, no he tenido problemas modificando los meta código-fuentes y construyendo mis ensayos desde la línea de comandos.
Convencerme que no soy yo el problema.
Si bien, lo admito, tiene que haber “una forma”, no la encuentro, así que con el propósito de convencerme que por lo menos aún soy capaz de pensar (bien), he realizado un brevísimo ensayo, en el cual construyo un lexer, casi totalmente a mano.
Pido disculpas por el “gol publicitario” pues s’e que muchos de los colegas no son precisamente aficionados a Microsoft®, pero mis auxiliares en este ensayo han sido los tan odiados como necesarios Word® y Excell®.
El ensayo está basado en el último ejemplo visto en clase(hasta ahora) de un autómata para reconocer operadores relacionales.
He construido mi propio autómata para reconocer operadores aritméticos, enteros positivos y paréntesis.
Recuerden que este es un lexer, así que no sabe NADA a cerca del orden en que estos elementos deben aparecer.
La primera fase, fue pensar los tipos de token a usar:
num = digito+
oper = [+-*/]
lpar = ‘(’
rpar = ‘)’
donde:
digito = [0123456789]
Con esto en mano (cabeza y necesariamente papel), procedí a crear el autómata. Importante notar, que el autómata debe ser determinista, ya que para este ensayo no disponía de ninguna herramienta para reducir un grafo cualquiera a DFA.
“Por favor disculpen lo burdo de este modelo, no tuve tiempo de hacerlo a escala” –Dr. Emmet Brown, Volver al Futuro.
Recuerden que un asterisco significa que se devuelve un caracter al input.
En este caso, el retorno de caracteres al input no parece congruente, lastimosamente, esto se debe a un detalle de la implementación, ya que mi autómata consume un caracter del input imediatamente que “llega” a un estado, para luego tomar la decisión a cerca de la siguiente transición. En este caso, supongamos que viene un ‘)’, el estado cero lee un caracter, luego internamente se da cuenta qué es y toma la transición al estado cuatro.
el estado cuatro lee inmediatamente un caracter, antes de saber que hará con él.
Pregunta clave en todo esto
¿Cómo programar el autómata?
Lo que procede es crear una tabla similar a la siguiente:
| Estado/Simbolo | ( | ) | + | - | * | / | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ' ' | $ | TOKEN |
| 0 | t,6 | t,5 | t,4 | t,4 | t,4 | t,4 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,0 | e | NINGUNO |
| 1 | *r | *r | *r | *r | *r | *r | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,2 | r,* | NUMERO |
| 2 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | r | *r | NUMERO |
| 3 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | NUMERO |
| 4 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | OPER |
| 5 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | RPAR |
| 6 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | LPAR |
Donde cada estado puede tomar una transición a un estado (t,4 significa transición al estado cuatro), o puede retornar un token. Si hay un asterisco significa devolver un caracter al input.
Noten que cada estado puede retornar como máximo un tipo de token, si aplica(estados finales). una tercera posibilidad, es que se dé un error, como en la casilla (0,$), (estado cero, símbolo $), que en este caso significa que en el estado cero, cualquier caracter que no sea [()+-*/0123456789] ó SPACE será rechazado.
Cada vez que el autómata alcanza un e. final, regresa al estado cero.
La tabla anterior la programé como un arreglo bidimensional de casillas especialmente diseñadas (struct) que contienen un parámetro para saber si se trata de una transición, un retorno, o un error, el estado siguiente, en caso de transición, y si debe o no hacer unget().
El arreglo lo llené a mano, pero para ello me auxilié de Word, Excel, y muchos “find & replace”, con lo que generé un lote de asignaciones que completan la tabla.
Para ver el auxilio en Excel, siga este enlace, vea la Hoja 2.
La idea de cómo trabaja el Autómata ya programado, finalmente, es la siguiente:
1) Se inicia en el estado cero.
2) Se lee un caracter del input
3) se evalúa la casilla correspondiente al caracter para el estado actual.
3.1) si hay que hacer unget() se hace
3.2) Se decide que sigue:
3.2.1) Si es transición, se cambia de estado
3.2.2) Si es retorno, se retorna el token correspondiente al estado(considere la última columna de la tabla como un arreglo que contiene el tipo de retorno para cada estado.
3.2.3) Si es error, se reporta.
Estos pasos se toman en un ciclo hasta que se consuma la totalidad del input.
Nota: en este ensayo, el símbolo $ significa “desconocido” cualquier letra no reconocida en las primeras columnas de la tabla, mapean a $ para efectos de escoger la casilla a tomar en cuenta.
Pueden seguir este enlace para ver el código fuente.
Puede compilar este código en un compilador de C/C++.
Yo utilicé Dev-C++ 4.01.
Para probarlo proporcione el input que conste de: Paréntesis, operadores [+-*/] y enteros positivos: [0-9]+.
La salida es una simulación de un stream de tokens, similar a lo que constituye el output de un lexer(input de un parser). Recuerde que el Lexer no sabe nada a cerca del orden de los tokens.
Lo importante de este ensayo:
Conclusiones.
Fue relativamente fácil realizar este ensayo, tomó aproximadamente 2 horas, pero esto se debe a lo limitado del input para el cual fue diseñado, cuatro tipos de tokens. Un lexer para muchos más tipos, consume más tiempo.
El autómata ha de hacerse a mano(cerebralmente), y reducirse a determinista, o pensarse determinista desde el principio. y luego traducirlo a la tabla.
Una vez resuelto el problema de cómo llenar la tabla(en el código), la programación del autómata es sencilla, toma poco tiempo, y es constante, es decir, un cambio en el léxico, sólo requiere un cambio a la tabla, ya que el algoritmo para recorrer el grafo es siempre el mismo.
La modificación de esa tabla, sin embargo, es muy delicada.
Otra observación que considero muy importante, es el hecho de que las expresiones regulares que definen los tipos de palabra, finalmente quedan en la tabla( representación en código fuente del lexer para el autómata). de donde es mucho más difícil leerlas de regreso, por lo cual, no se puede entender que tipo de tokens lee el lexer con solo ver el código.
Finalmente, Las tablas de análisis léxico para un lenguaje real, suelen ser muy grandes para manejarlas fácilmente, aún en Excel.
En resumen, existe una razón por la cual se ha creado la cantidad tan extensa de generadores de analizadores léxicos, la complejidad es alta, pero rutinaria. Recuerde el algoritmo para reducir un Autómata No Determinista a uno Determinista.
Una aproximación básica a la creación de un “creador de lexers” comprendería la programación necesaria para leer las expresiones regulares que definen los tipos de token, y traducirlos a la tabla final, pasando por el autómata determinista, a lo cual, habrá solamente que adosarle el código del algoritmo para recorrer el autómata y las funcionalidades para recuperar los tokens desde un parser u otro programa.
Notas
La tabla que presento aquí, es parte de un tópico que se trata más adelante en el curso, sin embargo, debo aclarar que la terminología y técnicas usadas no son las mismas que en el Libro principal del curso, ya que adapté algunas partes para facilitarme la realización en corto tiempo. También el llamar Transición o Retorno a las casillas de la tabla, como más adelante se verá, es en realidad lo que se conoce como “Shift/Reduce”.
lunes, agosto 08, 2005
Reporte de Laboratorio Sección C:
Reporte de Laboratorio Sección C:
Creación de un proyecto básico que incluya jFlex y CUP
Primero: Pegar Eclipse con jFlex
Este primer paso se logró configurando como Builder el archivo por lotes que se encuentra en
C:\cmpl\JFlex\bin\jflex.bat
especificando como directorio de trabajo:
${workspace_loc:/jFlexPrueba}
que es el directorio del proyecto creado en Eclipse, y finalmente, dando como argumento el nombre del archivo léxico:
${resource_name:/jFlexPrueba/experimental.lex}
Notas: Esto después de muchos intentos, ya que las instrucciones mencionan “como tipo External Tool”, tipo que no encontré, solamente vi disponibles «Ant Build» y «Program»
Inicialmente intenté con «Ant Build». “Ahí fue donde la mula botó a Genaro”, ya que me vi nuevamente ante una avalancha de configuraciones y parámetros...
Después recordé que para ejecutar jFlex hay dos opciones: una que implica el .jar, y otra que se hace desde el .bat. De modo que eliminé ese builder y agregué otro, esta vez de tipo «Program».
Utilicé primeramente el archivo .bat sin argumentos, y tuve que lidiar con el cuadro de diálogo de jFlex cada vez que a Eclipse se le ocurría hacer un Build. Por eso me demoré lo menos posible en colocarlos argumentos que indiqué al principio.
Observaciones uno
Una vez trazada la línea primera, logré hacer que Eclipse genere a Yylex.java, al examinar el código generado pude constatar que no difiere notablemente (al ojo humano) del que se generó en la parte anterior de la práctica, ya que experimental.lex es en realidad el mismo que minimal.lex.
Segundo: Pegar java_cup con Eclipse
De inicio, java_cup no tiene un .bat o un .jar entre sus directorios, sólo una cantidad considerablemente grande de archivos fuente, por lo cual intenté agregando el directorio de los mismos al « Build Path », sin resultados.
domingo, agosto 07, 2005
Otros Comentarios sobre el Laboratorio
Primeramente debo aclarar, éste laboratorio fue mucho más interesante que el relacionado con ANTLR en el semestre pasado
Antes que lo olvide... aquí esta la versión en word del post anterior.
Aunque aun quedé un tanto confundido porque algunos de los problemas “se arreglaron solos” (Las computadoras a veces parecen no deterministas), fue un reto el tener que luchar contra herramientas desconocidas, lo cual no sucedió con ANTLR.
Hubo muchas dudas en lo referente a las líneas de comandos, ya que en comunicaciones entre compañeros, esas eran las preguntas más frecuentes.
Lo más extraño que maquinas muy similares, con la misma versión de JVM, sistema Operativo, Service Pack, etc. En unas funciona, y en otras no.
A mi me parece un MITO esa portabilidad que predica java, porque de una versión a la siguiente de la JVM hay que cambiar el código o hacer algún arreglo. Y ya entre plataformas distintas... no digamos.
Por cierto, en el post anterior hay una línea que dice:
La descarga y/o copia de los archivos requeridos se realizó son problemas.
Debe leerse:
La descarga y/o copia de los archivos requeridos se realizó sin problemas.
“Otro desafortunado efecto del hambre”
Debo agregar, que por mucho que me haya gustado el laboratorio, sentí muy confusas las instrucciones, y creo que no hablo (escribo) sólo por mí, ya que muchos compañeros me llamaron, preguntando...
La documentación de jFlex también me pareció confusa, [ y extensa ]. Una compañera utilizó el término “blurry”. En rosado y todo!!! (si alguien me lo traduce...)
En fin... el uso de los Paths en este laboratorio resultó algo inesperadamente dificultoso. Creo que el problema se debió a que no se captaba el concepto general de lo que se estaba haciendo con los .bat.
De hecho, uno de los compañeros, terminó escribiendo a mando los paths directamente en la consola, ya que los .bat no le resultaron.
En mi caso, quise elaborar un .bat para regenerar en un solo paso todos los archivos, tan sencillo como esto:
------------------------------
jflex minimal.lex
java java_cup.Main minimal.cup
javac -d . parser.java sym.java Yylex.java
----------------------------
Pero al parecer, las dos últimas líneas se metían como parámetros del primer programa, por lo cual sólo éste de ejecutaba, así que tuve que optar por aprovechar el buffer de instrucciones recientes del CMD.exe. (la tecla de flecha hacia arriba).
Al fin y al cabo... el que persevera alcanza, y ¡caballo que alcanza, gana!
![]()
