domingo, agosto 14, 2005
Un lexer hecho a mano
EL proyecto de “Turbo Dragon” está en peligro de extinción.
Aún sigo sin poder conectar efectivamente las herramientas de generación de código con Eclipse. La situación resulta bastante frustrante, para una estudiante de la carrera donde “todo se puede”. Es por esto que he tomado una decisión, de ninguna manera me voy a dejar “ECLIPSAR” por un IDE superconfigurable, así que si mr. E. sigue rebelde, doña Consola, que no me defrauda, me será más que suficiente para hacer un compilador.
En efecto, no he tenido problemas modificando los meta código-fuentes y construyendo mis ensayos desde la línea de comandos.
Convencerme que no soy yo el problema.
Si bien, lo admito, tiene que haber “una forma”, no la encuentro, así que con el propósito de convencerme que por lo menos aún soy capaz de pensar (bien), he realizado un brevísimo ensayo, en el cual construyo un lexer, casi totalmente a mano.
Pido disculpas por el “gol publicitario” pues s’e que muchos de los colegas no son precisamente aficionados a Microsoft®, pero mis auxiliares en este ensayo han sido los tan odiados como necesarios Word® y Excell®.
El ensayo está basado en el último ejemplo visto en clase(hasta ahora) de un autómata para reconocer operadores relacionales.
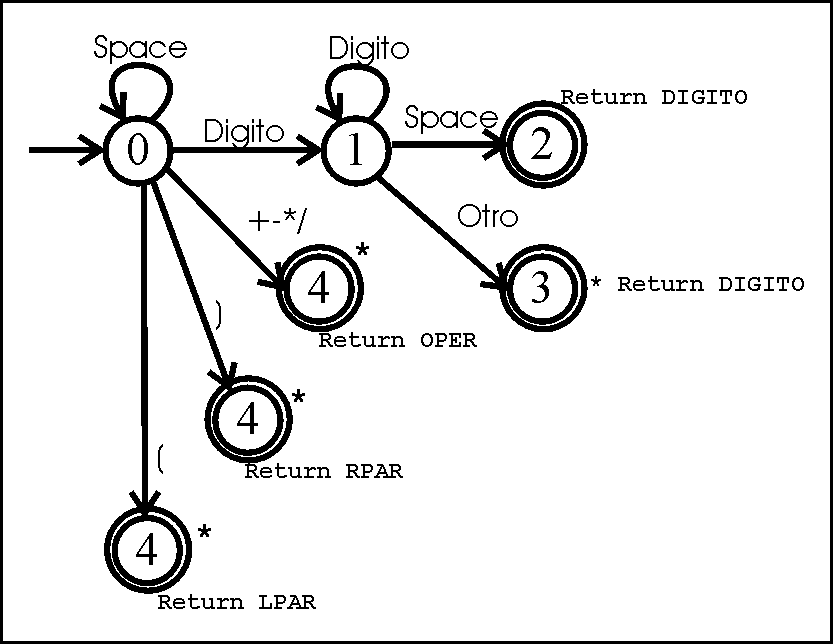
He construido mi propio autómata para reconocer operadores aritméticos, enteros positivos y paréntesis.
Recuerden que este es un lexer, así que no sabe NADA a cerca del orden en que estos elementos deben aparecer.
La primera fase, fue pensar los tipos de token a usar:
num = digito+
oper = [+-*/]
lpar = ‘(’
rpar = ‘)’
donde:
digito = [0123456789]
Con esto en mano (cabeza y necesariamente papel), procedí a crear el autómata. Importante notar, que el autómata debe ser determinista, ya que para este ensayo no disponía de ninguna herramienta para reducir un grafo cualquiera a DFA.
“Por favor disculpen lo burdo de este modelo, no tuve tiempo de hacerlo a escala” –Dr. Emmet Brown, Volver al Futuro.
Recuerden que un asterisco significa que se devuelve un caracter al input.
En este caso, el retorno de caracteres al input no parece congruente, lastimosamente, esto se debe a un detalle de la implementación, ya que mi autómata consume un caracter del input imediatamente que “llega” a un estado, para luego tomar la decisión a cerca de la siguiente transición. En este caso, supongamos que viene un ‘)’, el estado cero lee un caracter, luego internamente se da cuenta qué es y toma la transición al estado cuatro.
el estado cuatro lee inmediatamente un caracter, antes de saber que hará con él.
Pregunta clave en todo esto
¿Cómo programar el autómata?
Lo que procede es crear una tabla similar a la siguiente:
| Estado/Simbolo | ( | ) | + | - | * | / | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ' ' | $ | TOKEN |
| 0 | t,6 | t,5 | t,4 | t,4 | t,4 | t,4 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,0 | e | NINGUNO |
| 1 | *r | *r | *r | *r | *r | *r | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,1 | t,2 | r,* | NUMERO |
| 2 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | r | *r | NUMERO |
| 3 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | NUMERO |
| 4 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | OPER |
| 5 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | RPAR |
| 6 | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | *r | LPAR |
Donde cada estado puede tomar una transición a un estado (t,4 significa transición al estado cuatro), o puede retornar un token. Si hay un asterisco significa devolver un caracter al input.
Noten que cada estado puede retornar como máximo un tipo de token, si aplica(estados finales). una tercera posibilidad, es que se dé un error, como en la casilla (0,$), (estado cero, símbolo $), que en este caso significa que en el estado cero, cualquier caracter que no sea [()+-*/0123456789] ó SPACE será rechazado.
Cada vez que el autómata alcanza un e. final, regresa al estado cero.
La tabla anterior la programé como un arreglo bidimensional de casillas especialmente diseñadas (struct) que contienen un parámetro para saber si se trata de una transición, un retorno, o un error, el estado siguiente, en caso de transición, y si debe o no hacer unget().
El arreglo lo llené a mano, pero para ello me auxilié de Word, Excel, y muchos “find & replace”, con lo que generé un lote de asignaciones que completan la tabla.
Para ver el auxilio en Excel, siga este enlace, vea la Hoja 2.
La idea de cómo trabaja el Autómata ya programado, finalmente, es la siguiente:
1) Se inicia en el estado cero.
2) Se lee un caracter del input
3) se evalúa la casilla correspondiente al caracter para el estado actual.
3.1) si hay que hacer unget() se hace
3.2) Se decide que sigue:
3.2.1) Si es transición, se cambia de estado
3.2.2) Si es retorno, se retorna el token correspondiente al estado(considere la última columna de la tabla como un arreglo que contiene el tipo de retorno para cada estado.
3.2.3) Si es error, se reporta.
Estos pasos se toman en un ciclo hasta que se consuma la totalidad del input.
Nota: en este ensayo, el símbolo $ significa “desconocido” cualquier letra no reconocida en las primeras columnas de la tabla, mapean a $ para efectos de escoger la casilla a tomar en cuenta.
Pueden seguir este enlace para ver el código fuente.
Puede compilar este código en un compilador de C/C++.
Yo utilicé Dev-C++ 4.01.
Para probarlo proporcione el input que conste de: Paréntesis, operadores [+-*/] y enteros positivos: [0-9]+.
La salida es una simulación de un stream de tokens, similar a lo que constituye el output de un lexer(input de un parser). Recuerde que el Lexer no sabe nada a cerca del orden de los tokens.
Lo importante de este ensayo:
Conclusiones.
Fue relativamente fácil realizar este ensayo, tomó aproximadamente 2 horas, pero esto se debe a lo limitado del input para el cual fue diseñado, cuatro tipos de tokens. Un lexer para muchos más tipos, consume más tiempo.
El autómata ha de hacerse a mano(cerebralmente), y reducirse a determinista, o pensarse determinista desde el principio. y luego traducirlo a la tabla.
Una vez resuelto el problema de cómo llenar la tabla(en el código), la programación del autómata es sencilla, toma poco tiempo, y es constante, es decir, un cambio en el léxico, sólo requiere un cambio a la tabla, ya que el algoritmo para recorrer el grafo es siempre el mismo.
La modificación de esa tabla, sin embargo, es muy delicada.
Otra observación que considero muy importante, es el hecho de que las expresiones regulares que definen los tipos de palabra, finalmente quedan en la tabla( representación en código fuente del lexer para el autómata). de donde es mucho más difícil leerlas de regreso, por lo cual, no se puede entender que tipo de tokens lee el lexer con solo ver el código.
Finalmente, Las tablas de análisis léxico para un lenguaje real, suelen ser muy grandes para manejarlas fácilmente, aún en Excel.
En resumen, existe una razón por la cual se ha creado la cantidad tan extensa de generadores de analizadores léxicos, la complejidad es alta, pero rutinaria. Recuerde el algoritmo para reducir un Autómata No Determinista a uno Determinista.
Una aproximación básica a la creación de un “creador de lexers” comprendería la programación necesaria para leer las expresiones regulares que definen los tipos de token, y traducirlos a la tabla final, pasando por el autómata determinista, a lo cual, habrá solamente que adosarle el código del algoritmo para recorrer el autómata y las funcionalidades para recuperar los tokens desde un parser u otro programa.
Notas
La tabla que presento aquí, es parte de un tópico que se trata más adelante en el curso, sin embargo, debo aclarar que la terminología y técnicas usadas no son las mismas que en el Libro principal del curso, ya que adapté algunas partes para facilitarme la realización en corto tiempo. También el llamar Transición o Retorno a las casillas de la tabla, como más adelante se verá, es en realidad lo que se conoce como “Shift/Reduce”.

<< Home
![]()
